

Earlier this month, AI safety and research company Anthropic announced that it was launching three new models for Claude, its generative AI assistant and family of large language models (LLMs). The new models would offer increasingly powerful performance to its users. Costs for each model are correlated with model intelligence and the number of tokens required to support processing power.
The most sophisticated Claude 3 model, Opus, exhibited “near-human levels of comprehension and fluency” on more complex tasks, and would come out ahead of Anthropic’s peers (including OpenAI’s GPT-4 or Google’s Gemini Ultra) on a number of benchmarks, including grade school math, code, or reasoning over text. One of the more unique elements of the launch was the reduction in incorrect refusals on behalf of Claude models; from Threads:
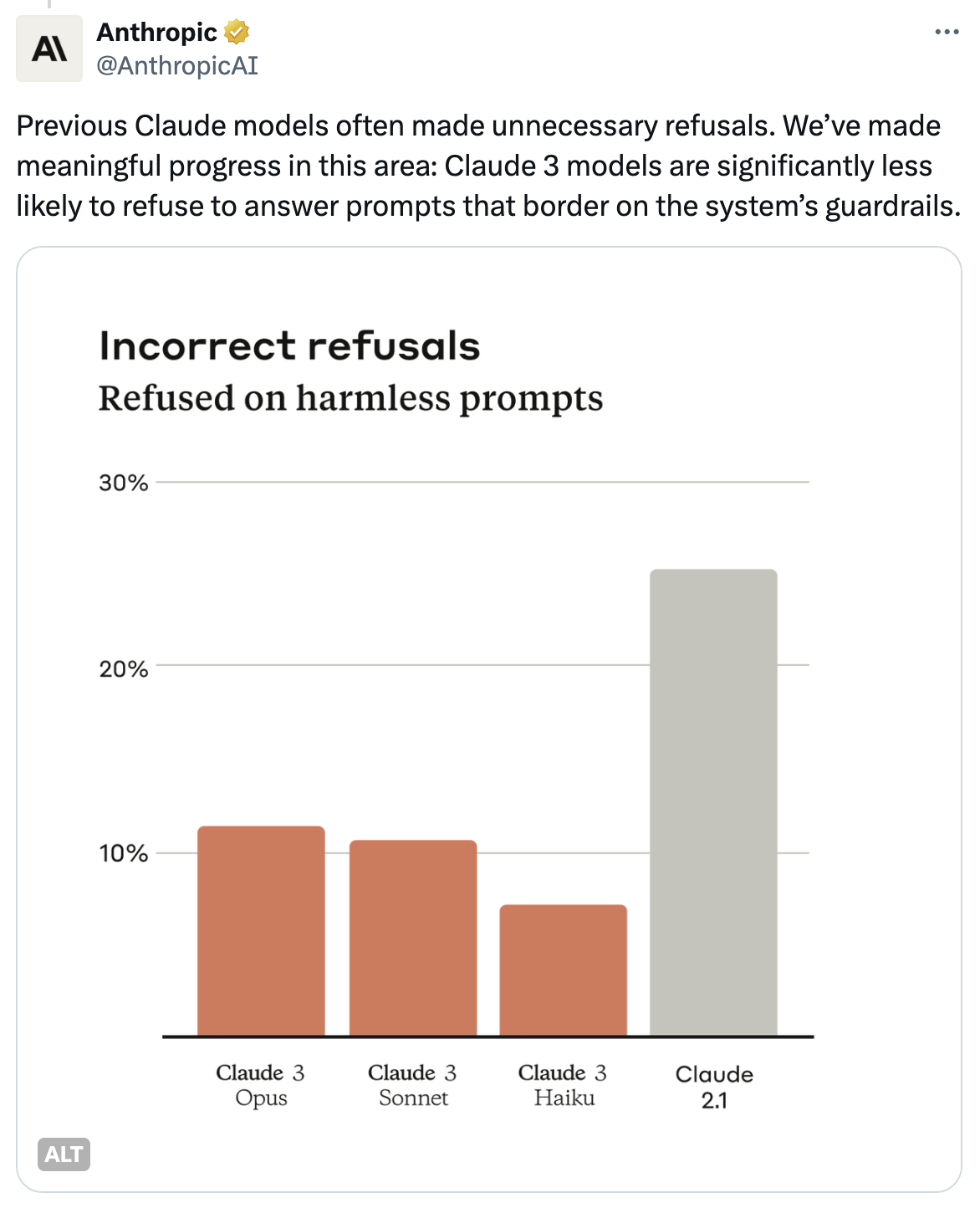
This is a significant (and exciting!) development, but questions remain as to whether the velocity in innovation for AI startups can offset the time it takes them to scale. As generative AI models like Claude 3 improve across the board, their incremental improvements run the risk of being overshadowed by broader concerns about the commercial viability of these platforms and their impact on labor.
Calculating the economic viability of AI
In a January study by the Massachusetts Institute of Technology, researchers engaged in a comparison of human and AI costs to explore what tasks were most cost-effective to automate, or those which are most at risk of “AI exposure.” In the report, the authors used the concept of minimum viable scale as the methodology for their comparison:
[This] occurs when the AI deployment’s fixed costs are sufficiently amortized that the average cost of using the computer vision system is the same as the cost of human labor of equivalent capacity. AI automation is cost-effective only when the deployment scale is larger than the minimum viable scale.

The researchers were not interested in the absolute costs of large AI models, but the relative costs at minimum viable scale to determine the economic advantage, or the costs proportional with displacement of human labor. In other words, instead of evaluating the economic impact of AI models by looking at the potential for AI to affect an area (and from there, extrapolating the pace of automation), a truly comprehensive impact assessment would have to look at the scale of labor displacement given the improved productivity of these models.
The study concluded that while job displacement would be substantial, it would also be gradual—and that U.S. firms today would likely not choose to automate most tasks with AI exposure, with “only 23% of worker wages being paid for vision tasks would be attractive to automate.” Since less than a quarter of workers could be effectively displaced at current dollar wages, the researchers claimed there is still room for policy and retraining to mitigate the negative impacts of increasingly productive AI models.
What does this mean for the commercial viability of the AI space? Instead of relying on absolute valuation figures, we need to look at these platforms’ valuation multiples, or ratios that provide a comparative measure of their market value relative to financial performance. The table below shows such multiples for selected AI startups.
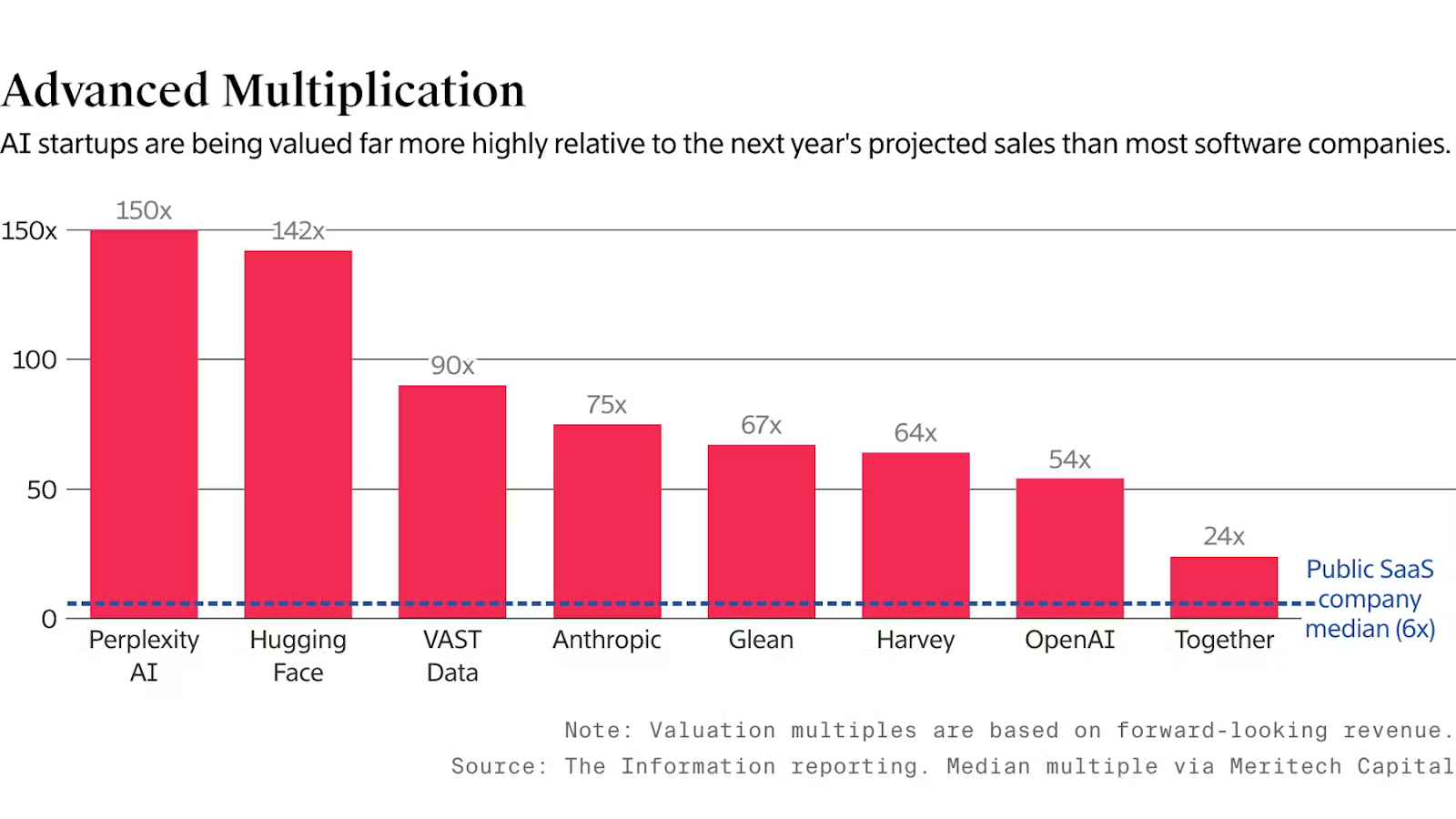
Valuation multiples for selected AI startups (The Information)
These multiples are based on forward-looking revenue, and can be assessed with metrics like price-to-sales (P/S) or price-to-earnings growth (PEG) ratios, which would give investors insight into the expected growth and profitability of AI companies in contrast with their current market valuation.
While most publicly-traded SaaS companies operate at a valuation multiple of ~6x relative to their projected sales in the following year, many AI startups are valued far higher. This reflects both market expectations and the transformative potential of these companies, who are backed in large part by major cloud providers. Google and Amazon, for instance, have both committed billions of dollars to Anthropic, and in turn sell its software to their cloud customers. The most well-known example comes from Microsoft’s partnership with OpenAI; from The Information:
As a cloud provider, Microsoft rents cloud servers to OpenAI at a relatively low margin, compared to other Microsoft cloud customers, said a person with knowledge of the situation. That helps keep down OpenAI’s server costs. As part of their deal, though, OpenAI must give Microsoft a cut of its direct sales to customers. And when Microsoft sells OpenAI software to its own cloud customers, it keeps a majority of revenue from those sales for itself. That could potentially become a problem as Microsoft increasingly draws enterprise customers that would otherwise buy software directly from OpenAI. The trend is likely eating into the startup’s growth rate.
For AI developers, the billion-dollar question is how quickly computing costs will continue to fall. Already, AI firms such as OpenAI have said they’ve cut the cost of running their AI models substantially over the past year by implementing new techniques for structuring the models, for instance. AI developers may also find it easier to run their models on cheaper servers rather than pay a pretty penny for state-of-the-art NVIDIA servers. At the same time, it’s hard to predict such cost drops, as emerging models that are more computationally efficient could replace OpenAI’s LLMs.
Other than the costly nature of developing their software, some AI startups are already under reputational scrutiny due to their dependence on third-party data and technologies, which raises questions about long-term durability. Perplexity, an AI-powered search engine, positions itself as an alternative to Google by offering more concise and accurate answers—all while using Google data (including ranking signals) to answer users’ questions.
The pillars of competitive edge
These startups’ lofty valuations will require them to not just sustain rapid revenue growth, but to navigate the complex ethical, regulatory, and technical challenges inherent in AI development and deployment. Foremost among these are the concepts of AI ethics, safety, and mitigation of potential harms.
Anthropic has made mitigating AI dangers a key part of its brand, and late last year published a responsible scaling policy to demonstrate their commitment to risk management protocols. The notion that these models could cause large scale devastation (colloquially known as p(doom), or the probability that AI could act contrary to the intents of its designers and cause a doomsday scenario) is central to this policy, with higher safety levels requiring stricter demonstrations of safety; from Anthropic:

View of AI safety levels by model capability (Anthropic)
There are two ways to regulate safety levels. The first is internally:
We have designed the ASL system to strike a balance between effectively targeting catastrophic risk and incentivising beneficial applications and safety progress. On the one hand, the ASL system implicitly requires us to temporarily pause training of more powerful models if our AI scaling outstrips our ability to comply with the necessary safety procedures. But it does so in a way that directly incentivizes us to solve the necessary safety issues as a way to unlock further scaling, and allows us to use the most powerful models from the previous ASL level as a tool for developing safety features for the next level. If adopted as a standard across frontier labs, we hope this might create a “race to the top” dynamic where competitive incentives are directly channeled into solving safety problems.
That said, relying on reputational risk alone to deter AI risks is short-sighted. OpenAI and Anthropic have worked closely with AI safety nonprofit Model Evaluation and Threat Research (METR) to safety-test their models. One way to achieve this is to evaluate their ability to make copies of themselves, known as self-replication. Beth Barnes, METR’s founder and CEO, claims that even though this ability does not yet exist, “it seems pretty hard to be confident that it’s not gonna happen within five years.” Today, researchers can determine these models’ propensity for self-replication by supplying them with prompts that produce the highest possible performance in conjunction with tools that could assist them to self-replicate.
Regulators are not sitting idle. In early November, the Biden administration signed an Executive Order requiring companies developing AI models to disclose the results of safety tests. And on Thursday, the United Nations passed a resolution on artificial intelligence calling on all member states to ensure “safe, secure, and trustworthy AI systems” developed responsibly, and with the right guardrails to ensure adherence to human rights and international laws.
While these resolutions achieve a baseline level of consensus, that could also be viewed as diluting their eventual impact. It is unclear under the Executive Order what the implications might be for a company that determined its model to be unsafe. The UN’s resolution notably excluded military applications for AI.
The race to develop and deploy generative AI technologies is a complex balancing act of innovation, ethics, and economics. That means the measure of success for existing players (and new entrants) is not just to craft an economically viable technology or be a first-mover. Rather, these companies need defensible differentiators—and that starts with adhering to internally- and externally-regulated thresholds for safety to minimize p(doom). Those which continue to publish safety reports and make research the cornerstone of their brand will inevitably succeed in the long-run.
